3rd Workshop on Language for 3D Scenes
ICCV 2023 Workshop
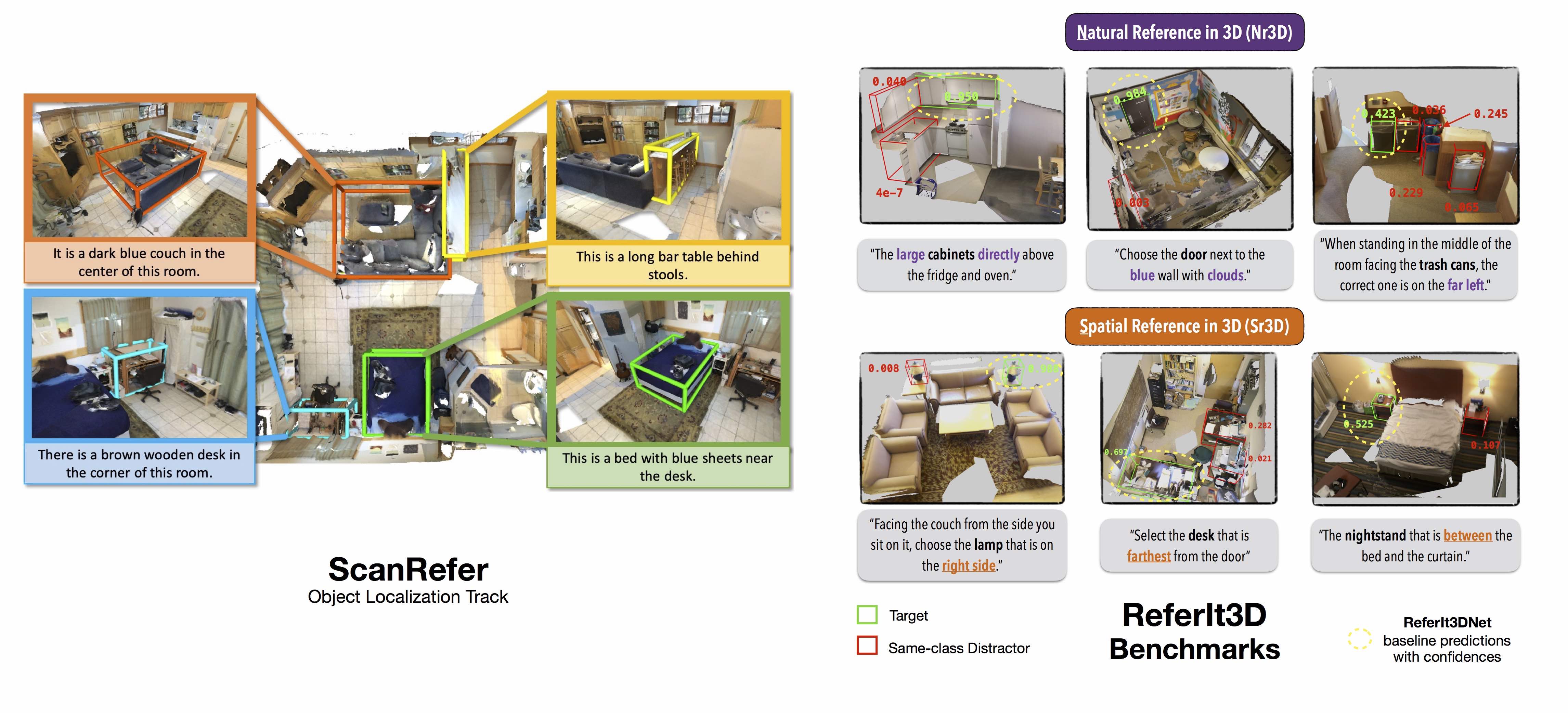
Introduction
This is the third workshop on natural language and 3D-oriented object understanding of real-world scenes. Our primary goal is to spark research interest in this emerging area, and we set two objectives to achieve this. Our first objective is to bring together researchers interested in natural language and object representations of the physical world. This way, we hope to foster a multidisciplinary and broad discussion on how humans use language to communicate about different aspects of objects present in their surrounding 3D environments. The second objective is to benchmark progress in connecting language to 3D to identify and localize 3D objects with natural language. Tapping on the recently introduced large-scale datasets of ScanRefer and ReferIt3D, we host two benchmark challenges on language-assisted 3D localization and identification tasks. The workshop consists of presentations by experts in the field and short talks regarding methods addressing the benchmark challenges designed to highlight the emerging open problems in this area.
Challenges
We establish four challenges:
- 3D Object Localization: to predict a bounding box in a 3D scene corresponding to an object described in natural language
- Fine-grained 3D Object Identification: to identify a referred object among multiple objects in a 3D scene given natural or spatial-based language
- 3D Dense Captioning: to predict the bounding boxes and the associated descriptions in natural language for objects in a 3D scene
- ScanEnts3D Challenge: This challenge measures the impact of exploiting the anchor objects found in referential sentences w.r.t. the task of 3D neural listening.
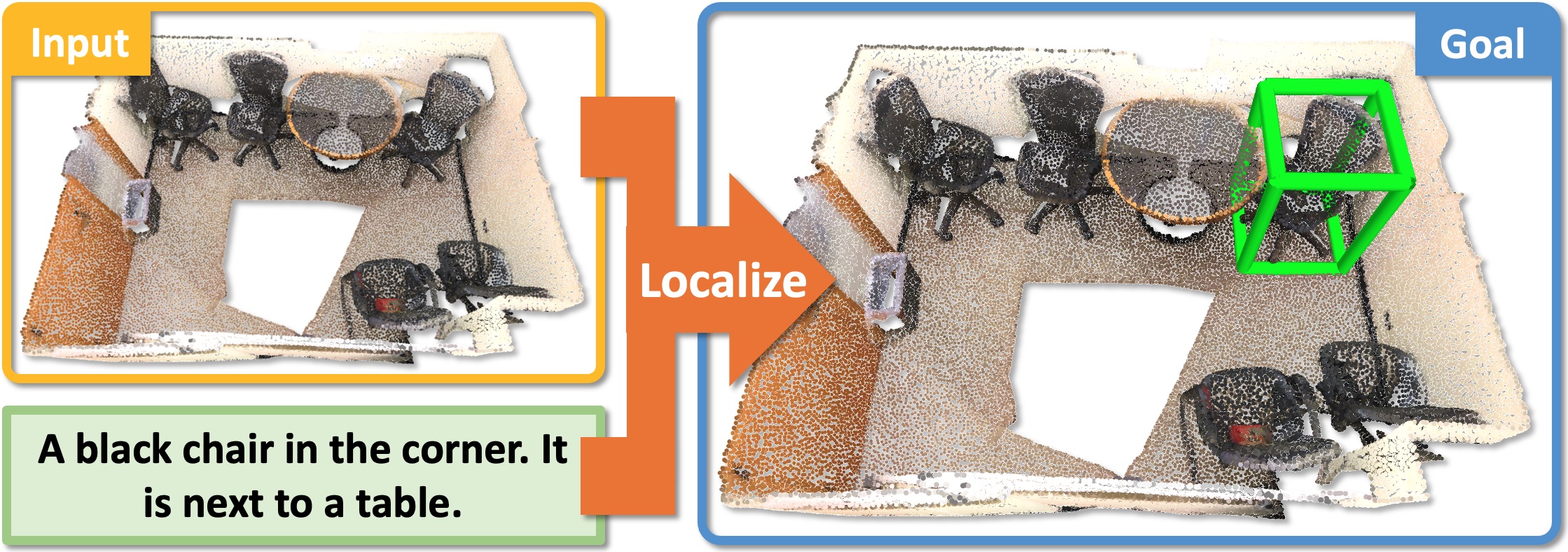
3D Object Localization

Fine-grained 3D Object Identification

3D Dense Captioning

ScanEnts3D Challenge
For each task the challenge participants are provided with prepared training, and test datasets, and automated evaluation scripts. The winner of each task will give a short talk describing their method during this workshop.
The challenge leaderboard is online. If you want to join the challenge, see more details here:
Call For Papers
Call for papers: We invite non-archival papers of up to 8 pages (in ICCV format) for work on tasks related to the intersection of natural language and 3D object understanding in real-world scenes. Paper topics may include but are not limited to:
- 3D Visual Grounding
- 3D Dense Captioning
- 3D Question Answering
- Leveraging language for 3D scene understanding
- Embodied Question Answering
Submission: We encourage submissions of up to 8 pages, excluding references and acknowledgements. The submission should be in the ICCV format. Reviewing will be single-blind. Accepted papers will be made publicly available as non-archival reports, allowing future submissions to archival conferences or journals. We welcome already published papers that are within the scope of the workshop (without re-formatting), including papers from the main ICCV conference. Please submit your paper to the following address by the deadline: language3dscenes@gmail.com Please mention in your email if your submission has already been accepted for publication (and the name of the conference).
Accepted Papers
| #1. PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image-Language Models Minghua Liu, Yinhao Zhu, Hong Cai, Shizhong Han, Zhan Ling, Fatih Porikli, Hao Su |
| #2. 3D Question Answering Shuquan Ye, Dongdong Chen, Songfang Han, Jing Liao |
| #3. PointCLIP V2: Prompting CLIP and GPT for Powerful 3D Open-world Learning Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyu Guo, Ziyao Zeng, Zipeng Qin, Shanghang Zhang, Peng Gao |
| #4. PLA: Language-Driven Open-Vocabulary 3D Scene Understanding Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, Xiaojuan Qi |
| #5. ViewRefer: Grasp the Multi-view Knowledge for 3D Visual Grounding Zoey Guo, Yiwen Tang, Ray Zhang, Dong Wang, Zhigang Wang, Bin Zhao, Xuelong Li |
| #6. OpenScene: 3D Scene Understanding with Open Vocabularies Songyou Peng, Kyle Genova, Chiyu "Max" Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser |
| #7. RefEgo: Referring Expression Comprehension Dataset from First-Person Perception of Ego4D Shuhei Kurita, Naoki Katsura, Eri Onami |
| #8. SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation Juil Koo, Seungwoo Yoo, Minh Hieu Nguyen, Minhyuk Sung |
| #9. 3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment Ziyu Zhu, Xiaojian Ma, Yixin Chen, Zhidong Deng, Siyuan Huang, Qing Li |
Important Dates (Paris / Pacific Time Zone)
| Call for papers & Workshop challenge announced | May 1 |
| Paper & challenge submission deadline | Aug 31 |
| Notifications to accepted papers & challenge winners | Sep 15 |
| Paper camera ready | Sep 22 |
| Workshop date | Oct 3 |
Schedule (Paris / Pacific Time Zone)
| Welcome | 2:00pm - 2:05pm / 5:00am - 4:05am |
| Invited Talk (Rana Hanocka) | 2:05pm - 2:30pm / 5:05am - 5:30am |
| Presentation of challenge winners | 2:30pm - 2:55pm / 5:30am - 5:55am |
| Poster session / Coffee break | 3:00pm - 3:25pm / 6:00am - 6:25am |
| Invited Talk (Chris Paxton) | 3:30pm - 4:00pm / 6:30am - 7:00am |
| Invited Talk (Or Litany) Talking to walls (...and other semantic categories) |
4:00pm - 4:25pm / 7:00am - 7:25am |
| Paper spotlights | 4:30pm - 4:55pm / 7:30am - 7:55am |
| Panel discussion | 5:00pm - 5:40pm / 8:00am - 8:40am |
| Concluding Remarks | 5:40pm - 5:50pm / 8:40am - 8:50am |
Invited Speakers

Rana Hanocka She is an Assistant Professor of Computer Science at the University of Chicago. She directs 3DL, a group of enthusiastic researchers passionate about 3D, machine learning, and visual computing. She obtained her Ph.D. in 2021 from Tel Aviv University under the supervision of Daniel Cohen-Or and Raja Giryes. Her research is focused on building artificial intelligence for 3D data, spanning the fields of computer graphics, machine learning, and computer vision. She had recent work on using text for stylizing meshes (Text2Mesh) and localizing regions on 3D shapes (3DHighlighter).

Or Litany He is a senior research scientist at NVIDIA and an incoming assistant professor at the Technion. Before that, he was a postdoc at Stanford University working under Prof. Leonidas Guibas, and FAIR working under Prof. Jitendra Malik. He received his PhD from Tel-Aviv University, where he was advised by Prof. Alex Bronstein. His research interests include deep learning for 3D vision and geometry and learning with reduced supervision. His recent work includes leveraging pretraining language-vision models for 3D scene understanding (ScanNet200).

Chris Paxton He is a robotics research scientist at FAIR Labs. He received his PhD in Computer Science in 2018 from the Johns Hopkins University in Baltimore, Maryland, focusing on using learning to create powerful task and motion planning capabilities for robots operating in human environments. From 2018-2022, he was with NVIDIA at their Seattle robotics lab. His recent work has been focusing on methods to tie together language, perception, and action in order to make robots into robust, versatile assistants for a variety of applications. His work include language grounding with 3D objects and modeling 3D scene representations with CLIP (CLIP-Fields).






