1st Workshop on Language for 3D Scenes
CVPR 2021 Workshop
The video recording of this workshop is here!
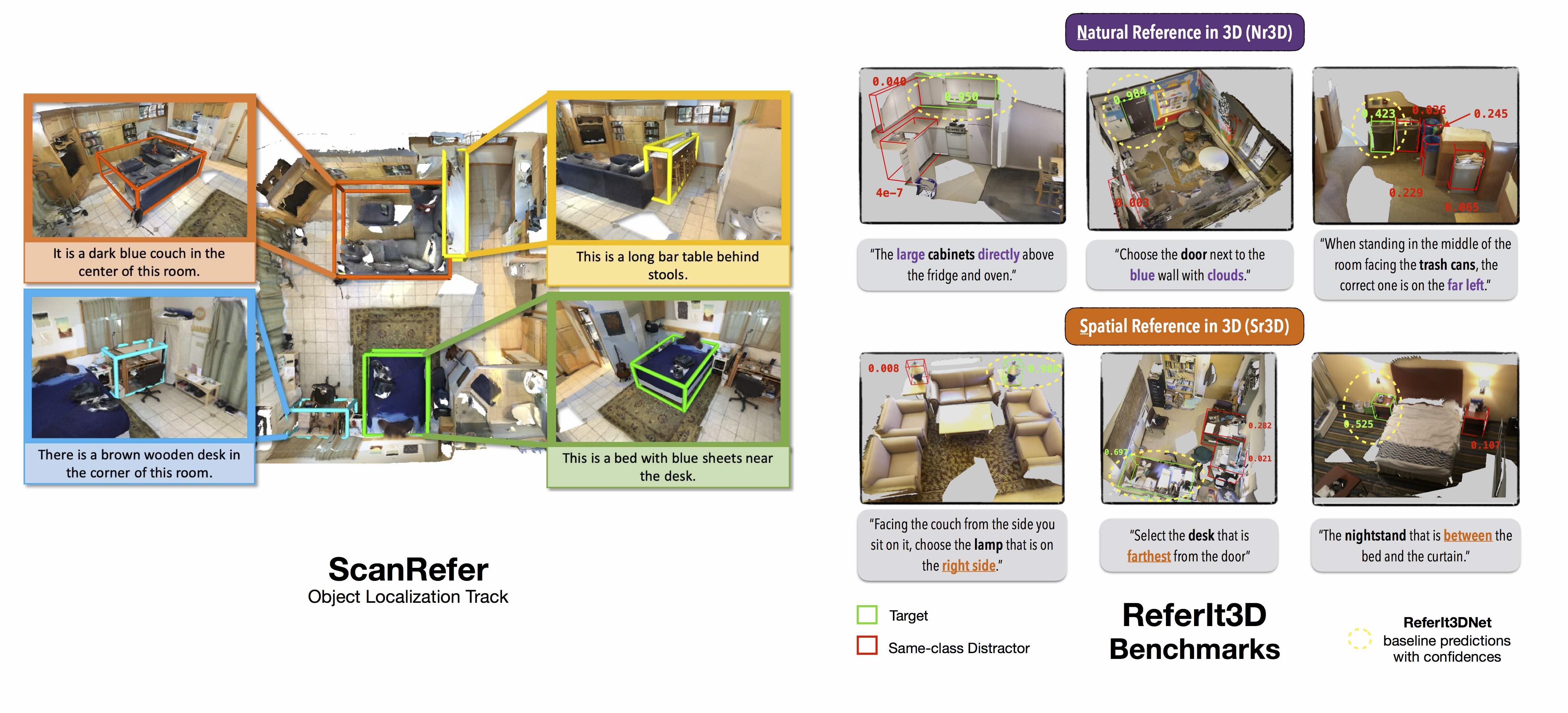
Introduction
This is the first workshop on natural language and 3D-oriented object understanding of real-world scenes. Our primary goal is to spark research interest in this emerging area, and we set two objectives to achieve this. Our first objective is to bring together researchers interested in natural language and object representations of the physical world. This way, we hope to foster a multidisciplinary and broad discussion on how humans use language to communicate about different aspects of objects present in their surrounding 3D environments. The second objective is to benchmark progress in connecting language to 3D to identify and localize 3D objects with natural language. Tapping on the recently introduced large-scale datasets of ScanRefer and ReferIt3D, we host two benchmark challenges on language-assisted 3D localization and identification tasks. The workshop consists of presentations by experts in the field and short talks regarding methods addressing the benchmark challenges designed to highlight the emerging open problems in this area.
Challenges
We establish two challenges:
- 3D Object Localization: to predict a bounding box in a 3D scene corresponding to an object described in natural language
- Fine-grained 3D Object Identification: to identify a referred object among multiple objects in a 3D scene given natural or spatial-based language
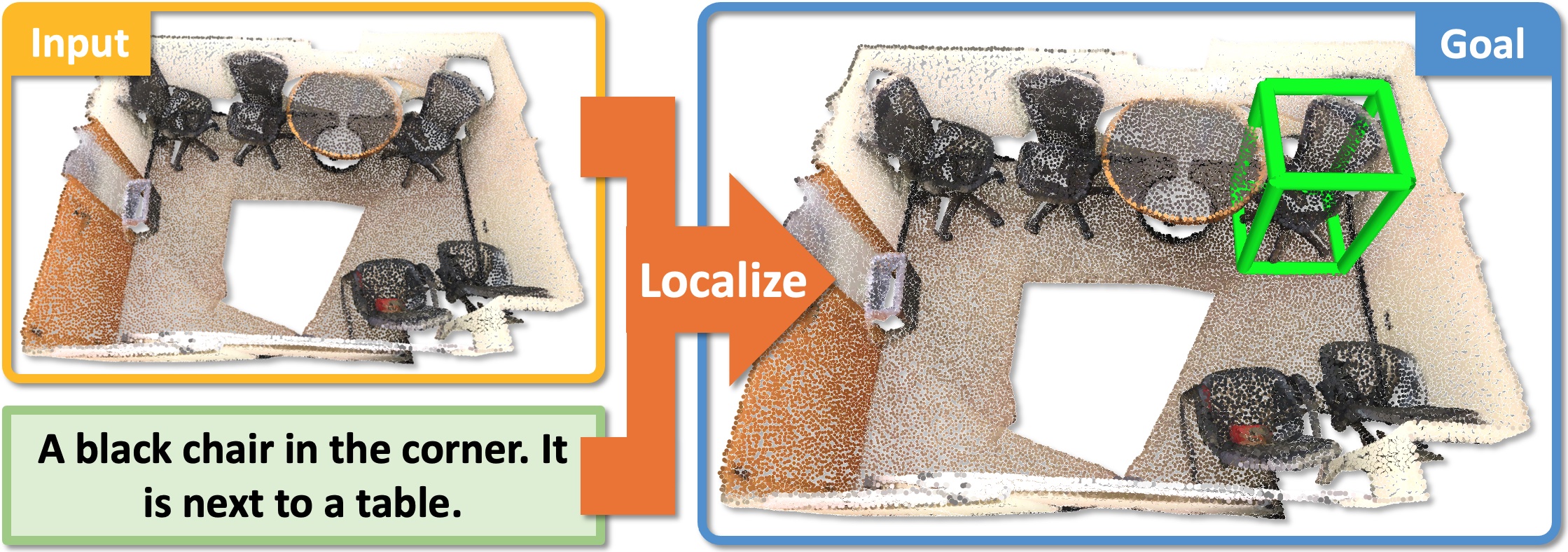
3D Object Localization

Fine-grained 3D Object Identification
For each task the challenge participants are provided with prepared training, and test datasets, and automated evaluation scripts. The winner of each task will give a short talk describing their method during this workshop.
The challenge leaderboard is online. If you want to join the challenge, see more details here:
Important Dates
| ScanRefer Challenge Submission Deadline | |
| Notification to ScanRefer Challenge Winner | |
| ReferIt3D Challenge Submission Deadline | |
| Notification to ReferIt3D Challenge Winner | |
| Workshop Date |
Schedule (Pacific Time Zone)
| Welcome and Introduction | 12:00 - 12:10 |
| From Disembodied to Embodied Grounded Language (Dhruv Batra) | 12:10 - 12:40 |
| Generating Animated Videos of Human Activities from Natural Language Descriptions (Raymond Mooney) | 12:40 - 13:10 |
| Winner Talk for ScanRefer | 13:10 - 13:20 |
| Affordances for Action in 3D Spaces (Kristen Grauman) | 13:20 - 13:50 |
| Break | 13:50 - 14:20 |
| The Semantics and Pragmatics of Reference to 3D Objects (Noah Goodman) | 14:20 - 14:50 |
| Winner Talk for ReferIt3D | 14:50 - 15:00 |
| Language Grounding Using Neural 3D Scene Representations (Katerina Fragkiadaki) | 15:00 - 15:30 |
| Panel Discussion and Conclusion | 15:30 - 16:00 |
Invited Speakers

Dhruv Batra is an Associate Professor in the School of Interactive Computing at Georgia Tech and a Research Scientist at Facebook AI Research (FAIR). His research interests lie at the intersection of machine learning, computer vision, natural language processing, and AI. The long-term goal of his research is to develop agents that 'see' (or more generally perceive their environment through vision, audition, or other senses), 'talk' (i.e. hold a natural language dialog grounded in their environment), 'act' (e.g. navigate their environment and interact with it to accomplish goals), and 'reason' (i.e., consider the long-term consequences of their actions). He is a recipient of the Presidential Early Career Award for Scientists and Engineers (PECASE) 2019.

Raymond Mooney is a Professor in the Department of Computer Science at the University of Texas at Austin. He received his Ph.D. in 1988 from the University of Illinois at Urbana/Champaign. He is an author of over 160 published research papers, primarily in the areas of machine learning and natural language processing. He was the President of the International Machine Learning Society from 2008-2011, program co-chair for AAAI 2006, general chair for HLT-EMNLP 2005, and co-chair for ICML 1990. He is a Fellow of the American Association for Artificial Intelligence, the Association for Computing Machinery, and the Association for Computational Linguistics and the recipient of best paper awards from AAAI-96, KDD-04, ICML-05 and ACL-07.

Kristen Grauman is a Professor in the Department of Computer Science at the University of Texas at Austin. Her primary research interests are visual recognition and visual search. Prior work of Kristen's considers large-scale image/video retrieval, unsupervised visual discovery, active learning, active recognition, first-person "egocentric" computer vision, interactive machine learning, image and video segmentation, activity recognition, vision and language, and video summarization. She has also recently established significant work on the novel problem of audio-visual understanding of scenes, and fundamental works concerning visual attributes of objects and fine-grained distinctions between them.

Noah Goodman is an Associate Professor of Psychology and Computer Science at Stanford University. He is interested in computational models of cognition, probabilistic programming languages, natural language semantics and pragmatics, and concepts and intuitive theories. He has extensive prior work in these fields and particularly relevant to this workshop, is his foundational work in the intersection of linguistics and human-inspired computational cognitive models.

Katerina Fragkiadaki is an Assistant Professor in the Machine Learning Department at Carnegie Mellon. Prior to joining MLD's faculty she worked as a postdoctoral researcher first at UC Berkeley working with Jitendra Malik and then at Google Research in Mountain View working with the video group. Katerina is interested in building machines that understand the stories that videos portray, and, inversely, in using videos to teach machines about the world. The penultimate goal is to build a machine that understands movie plots, and the ultimate goal is to build a machine that would want to watch Bergman over this.





