2nd Workshop on Language for 3D Scenes
ECCV 2022 Workshop
Introduction
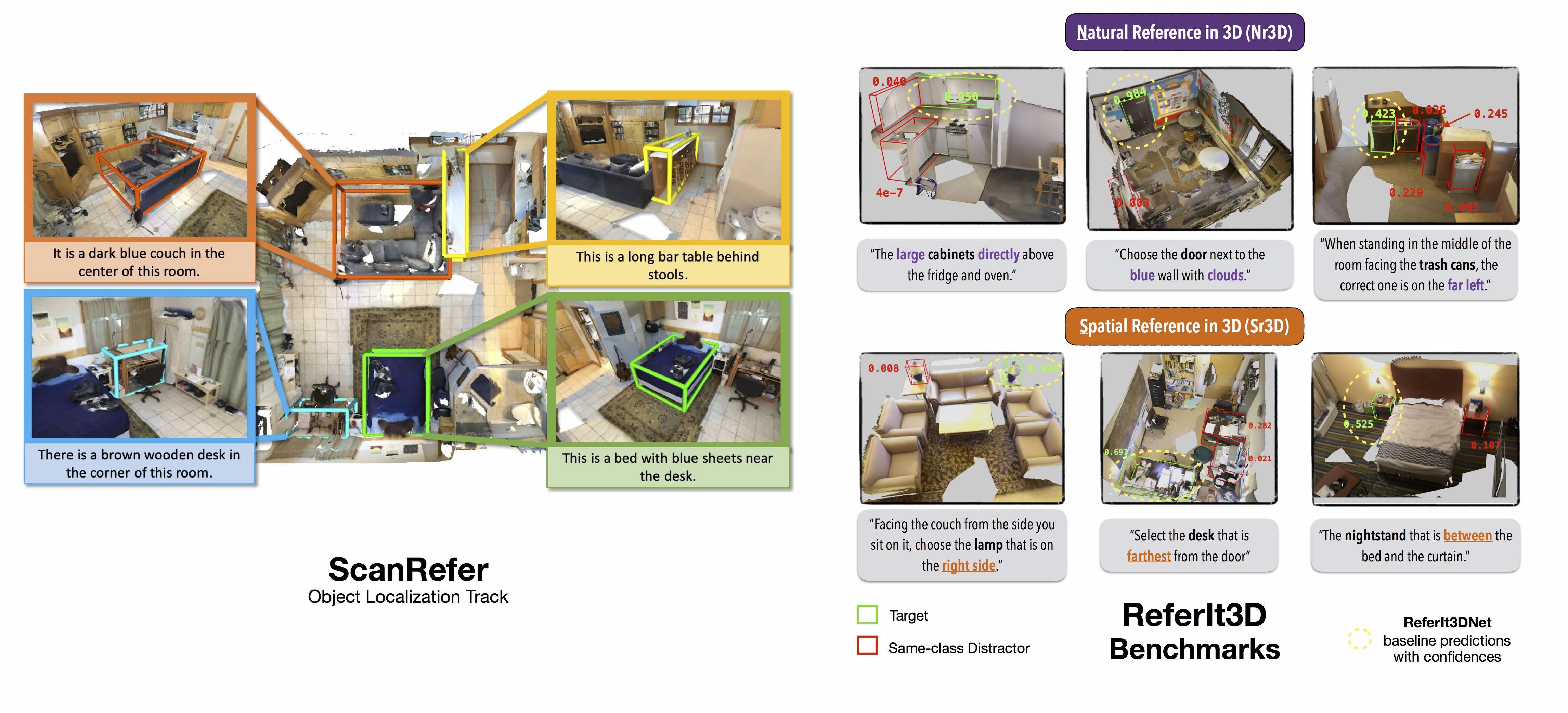
This is the second workshop on natural language and 3D-oriented object understanding of real-world scenes. Our primary goal is to spark research interest in this emerging area, and we set two objectives to achieve this. Our first objective is to bring together researchers interested in natural language and object representations of the physical world. This way, we hope to foster a multidisciplinary and broad discussion on how humans use language to communicate about different aspects of objects present in their surrounding 3D environments. The second objective is to benchmark progress in connecting language to 3D to identify and localize 3D objects with natural language. Tapping on the recently introduced large-scale datasets of ScanRefer and ReferIt3D, we host two benchmark challenges on language-assisted 3D localization and identification tasks. The workshop consists of presentations by experts in the field and short talks regarding methods addressing the benchmark challenges designed to highlight the emerging open problems in this area.
Challenges
We establish three challenges:
- 3D Object Localization: to predict a bounding box in a 3D scene corresponding to an object described in natural language
- Fine-grained 3D Object Identification: to identify a referred object among multiple objects in a 3D scene given natural or spatial-based language
- 3D Dense Captioning (new!): to predict the bounding boxes and the associated descriptions in natural language for objects in a 3D scene
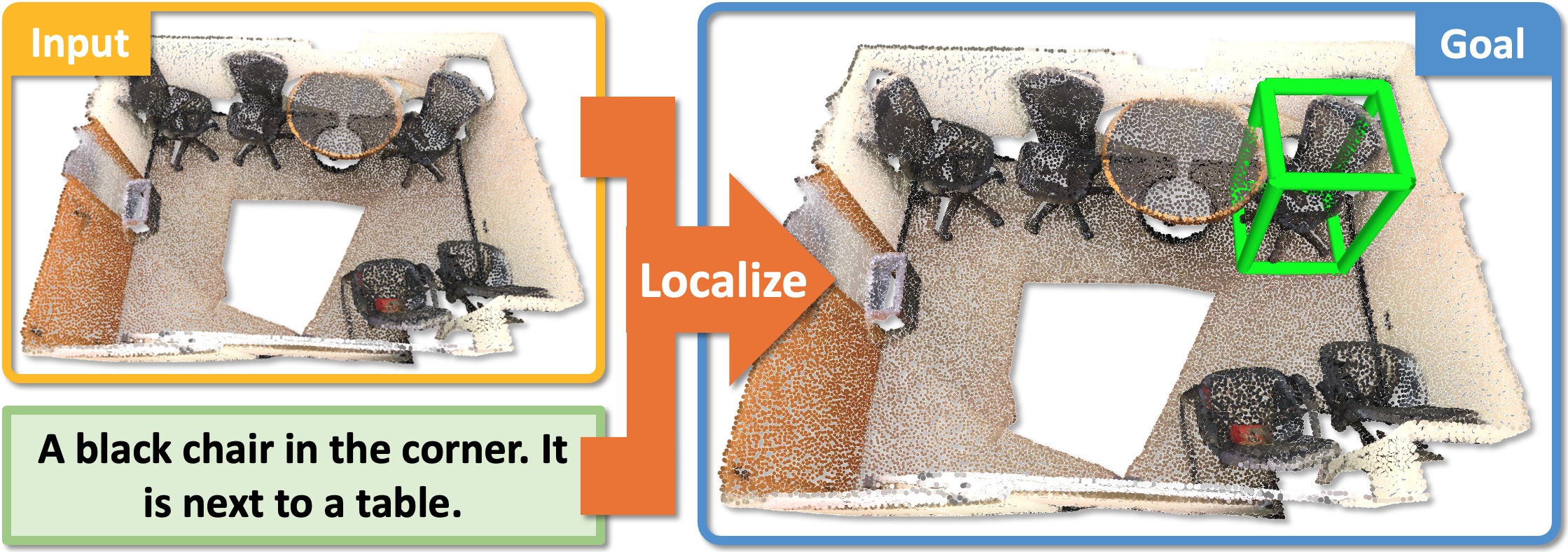
3D Object Localization

Fine-grained 3D Object Identification

3D Dense Captioning
For each task the challenge participants are provided with prepared training, and test datasets, and automated evaluation scripts. The winner of each task will give a short talk describing their method during this workshop.
The challenge leaderboard is online. If you want to join the challenge, see more details here:
Call For Papers
Call for papers: We invite non-archival papers of up to 14 pages (in ECCV format) for work on tasks related to the intersection of natural language and 3D object understanding in real-world scenes. Paper topics may include but are not limited to:
- 3D Visual Grounding
- 3D Dense Captioning
- 3D Question Answering
- Leveraging language for 3D scene understanding
- Embodied Question Answering
Submission: We encourage submissions of up to 14 pages, excluding references and acknowledgements. The submission should be in the ECCV format. Reviewing will be single-blind. Accepted papers will be made publicly available as non-archival reports, allowing future submissions to archival conferences or journals. We welcome already published papers that are within the scope of the workshop (without re-formatting), including papers from the main ECCV conference. Please submit your paper to the following address by the deadline: language3dscenes@gmail.com Please mention in your email if your submission has already been accepted for publication (and the name of the conference).
Accepted Papers
| #1. 3DJCG: A Unified Framework for Joint Dense Captioning and Visual Grounding on 3D Point Clouds Daigang Cai, Lichen Zhao, Jing Zhang, Lu Sheng, Dong Xu |
| #2. SQA3D: Situated Question Answering in 3D Scenes Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, Siyuan Huang |
| #3. PartGlot: Learning Shape Part Segmentation from Language Reference Games Juil Koo, Ian Huang, Panos Achlioptas, Leonidas Guibas, Minhyuk Sung |
| #4. EDA: Explicit Text-Decoupling and Dense Alignment for 3D Visual and Language Learning Yanmin Wu, Xinhua Cheng, Renrui Zhang, Zesen Cheng, Jian Zhang |
| #5. 3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection Junyu Luo, Jiahui Fu, Xianghao Kong, Chen Gao, Haibing Ren, Hao Shen, Huaxia Xia, Si Liu |
| #6. Bottom Up Top Down Detection Transformers for Language Grounding in Images and Point Clouds Ayush Jain, Nikolaos Gkanatsios, Ishita Mediratta, Katerina Fragkiadaki |
Important Dates
| ScanRefer Challenge Submission Deadline | Oct 13 2022 - AoE time (UTC -12) |
| Notification to ScanRefer Challenge Winner | Oct 14 2022 |
| ReferIt3D Challenge Submission Deadline | Oct 13 2022 - AoE time (UTC -12) |
| Notification to ReferIt3D Challenge Winner | Oct 14 2022 |
| Scan2Cap Challenge Submission Deadline | Oct 13 2022 - AoE time (UTC -12) |
| Notification to Scan2Cap Challenge Winner | Oct 14 2022 |
| Paper Submission Deadline | Sep 19 2022 - AoE time (UTC -12) |
| Notification to Authors | Sep 26 2022 |
| Camera-Ready Deadline | Oct 5 2022 |
| Workshop Date | Oct 23 2022 |
Schedule (Tel Aviv / Pacific Time Zone)
| Welcome | 2:00pm - 2:05pm / 4:00am - 4:05am |
| The Language of 3D Human Shape and Motion (Michael Black) | 2:05pm - 2:30pm / 4:05am - 4:30am |
| Concept Learning in 3D Dynamic Scene (Jiajun Wu) | 2:30pm - 2:55pm / 4:30am - 4:55am |
| Towards Human-like Understanding of Physical Scene Dynamics (Judith Fan) | 3:00pm - 3:25pm / 5:00am - 5:25am |
| Challenge results | 3:30pm - 4:00pm / 5:30am - 6:00am |
| Lightning paper presentations | 4:00pm - 4:10pm / 6:00am - 6:10am |
| Two Approaches to Grounded Language Evaluation (Alane Suhr) | 4:10pm - 4:35pm / 6:10am - 6:35am |
| Training Instruction-Following Agents with Synthetic Instructions (Peter Anderson) | 4:35pm - 5:00pm / 6:35am - 7:00am |
| Scene Representations for Language Grounding in Robotics (Valts Blukis) | 5:00pm - 5:25pm / 7:00am - 7:25am |
| Panel discussion | 5:30pm - 6:00pm / 7:30am - 8:00am |
Invited Speakers

Michael J. Black He is an Honorarprofessor at the University of Tuebingen and one of the founding directors at the Max Planck Institute for Intelligent Systems in Tübingen, Germany, where he leads the Perceiving Systems department. He was also a Distinguished Amazon Scholar (VP, 2017-2021). Black's research interests in computer vision include optical flow estimation, 3D shape models, human shape and motion analysis, robust statistical methods, and probabilistic models of the visual world. In computational neuroscience his work focuses on probabilistic models of the neural code and applications of neural decoding in neural prosthetics.

Valts Blukis is a Research Scientist at NVIDIA. He researches in the intersection of machine learning, natural language processing, computer vision, and robotics, with the goal to enhance robot capabilities to interact with people and accomplish tasks in unstructured environments. He focuses on systems that map raw first-person sensor observations and language to control.

Jiajun Wu is an Assistant Professor of Computer Science at Stanford University, affiliated with the Stanford Vision and Learning Lab (SVL) and the Stanford AI Lab (SAIL). He studies machine perception, reasoning, and interaction with the physical world, drawing inspiration from human cognition. Before joining Stanford, he was a Visiting Faculty Researcher at Google Research, New York City, working with Noah Snavely.

Peter Anderson is a research scientist in the Language team at Google Research. His research interests include computer vision, natural language processing and AI in general, and problems at the intersection of computer vision and natural language processing in particular. His recent work has focused on grounded language learning, particularly in large-scale visually-realistic 3D environments. He completed his PhD in Computer Science at Australian National University in 2018 where he was advised by Stephen Gould.

Judith Fan is an Assistant Professor in the Department of Psychology at UC San Diego. Her lab's research addresses questions at the intersection of cognitive science, computational neuroscience, and AI. As a central case study, their recent investigations focus on human visual communication, which encompasses behaviors ranging from informal sketching to formal scientific visualization and its applications in education, user interface design, and assistive technologies. Their goal in building computational models of such behaviors is to understand how perception, memory, motor planning, and social cognition functionally interact in the brain, leading to a more unified understanding of how multiple cognitive systems are coordinated during complex, natural behaviors.

Alane Suhr is a final-year PhD candidate in Computer Science at Cornell University, based at Cornell Tech in New York, NY. Her research spans natural language processing, machine learning, and computer vision. She builds systems that use language to interact with people, e.g., in collaborative interactions (like CerealBar). She designs models and datasets that address and represent problems in language grounding (e.g., NLVR). She also develops learning algorithms for systems that learn language through interaction.








